Differentiable and probabilistic programming for risk management and investment decisions
Some applications of differentiable programming in data science beyond the usual machine learning algorithms, with an example in drug development valuation.
differentiable programming
probabilistic programming
tensorflow-probability
quantitative finance
drug development
risk management
Author
Yves Barmaz
Published
November 11, 2023
Automatic differentiation and sensitivities
Differentiable programming is one of the technologies that have fueled the recent deep learning revolutions. It allows for the automatic computation of derivatives (gradients) of functions with respect to their inputs. This is particularly relevant for gradient-based optimization algorithms such as the ones commonly used to train machine learning models. In finance and business applications, differentiable programming can greatly simplify sensitivity analysis by removing the need to compute partial derivatives by hand. Concretely, if the value \(V\) of a certain contract depends for instance on a sales forecast \(S\) and some rate of return \(r\),
\[
V = f(S, r),
\]
the impact of small changes in the underlying variables can be estimated through a first-order approximation,
\[
\Delta V = \frac{\partial f}{\partial S} \Delta S + \frac{\partial f}{\partial r} \Delta r,
\]
which should be straightforward to compute in a differentiable programming library such as JAX through the application of the grad operator.
Sensitivity analysis is important to inform investment decisions and risk management, so there is no question here about the benefits of automatic differentiation. Furthermore, functions in differentiable programming are chainable, and derivatives automatically follow the chain rule. So if the sales forecast is given by another function, for instance sales_forecast_fn(temperature, store_location), one can compose them to find the sentivity to the temperature.
In particular, this also works when sales_forecast_fn is a differentiable machine learning model such as a neural network, so one can combine financial models with machine learning forecast models of their input variables.
Maybe more interestingly, the finance team can then focus on the value functions and their financial input, while the commercial team is responsible for the sales forecast, and the differentiable programming framework will ensure the compatibility of the models and the backpropagation of sensitivities.
Sidenote on discrete variables
The store_location variable was not used here because it is discrete and differentiation only works for continuous numerical variables. It was added as an example of a limitation of sensitivity analysis through automatic differentiation. In the case of discrete variables, the concept of “small change” does not make sense anyway, and analysing distributions of contract values conditioned on the store location is going to be informative enough for the purpose of risk management and investment decisions.
Probabilistic programming and Monte Carlo simulations
Even for continuous variables, sensitivity analysis through partial derivatives only works for small changes. The next stage of risk management is to build a probabilistic risk model of the joint distribution of input variables and estimate their effect on the output of the value function through Monte Carlo simulation.
This used to be a tedious process, especially with multiple correlated random variables. Surprisingly, differentiable programming has also indirectly simplified that process. The recent years have seen the development of several probabilistic programming libraries built on top of differentiable programming libraries. The reason is that automatic differentiation greatly facilitates the implementation of gradient-based inference algorithms such as Hamiltonian Monte Carlo and variational inference, so there has been a push to streamline the whole analysis process.
In probabilistic programming, probabilistic models are specified in computer code, and inference is performed more or less automatically. The probabilistic models prescribe ways to draw samples of the probability distributions they encode, and to evaluate the probability density of observations. In the context of risk management, it is enough to express the risk model as a probabilistic program, and the sampling methods will perform Monte Carlo simulations automatically, as illustrated in the following example.
Again, the composability of differentiable programs makes it easy to connect a risk model to other parts of an analytics pipeline.
Drug development
Estimating the value of a drug development program is the archetypical example of a valuation problem where probability distributions play an important role due to the stochastic nature of the whole process. Clinical development traditionally follows different trial phases to derisk the program medically and financially. The success of each phase determines if there will be investment in the next one, and ultimately if the drug will be commercialized and bring in revenue. The industry standard methodology for this valuation is the risk-adjusted net present value (rNPV), where every discounted future cash flow is weighted by the probability that it actually occurs. In other words, it is the expectation value of the random variable representing the sum of discounted future cash flows.
Sources of randomness in the NPV of a drug in development include the success or failure of different phases, that can be modelled by Bernoulli random variables, and the uncertainty in the parameters of the valuation model.
estimated cost
duration
success rate
stage
phase 1
4.0
1.0
0.66
phase 2
15.0
2.0
0.39
phase 3
45.0
2.0
0.62
regulatory submission
2.0
1.5
0.75
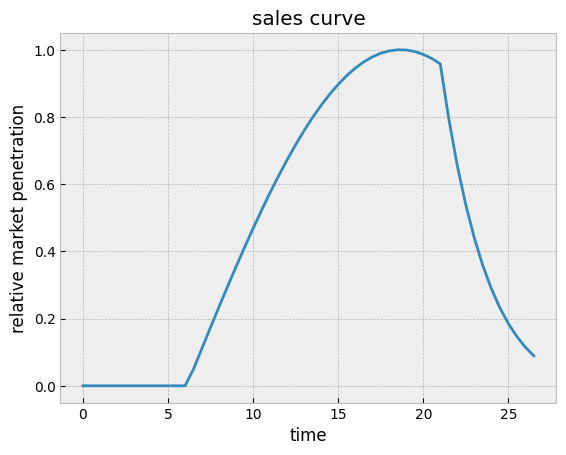
The volume of sales is particularly hard to estimate as it varies over time and the forecast has to be made a few years in advance. A common way to approach this problem, which was implemented in the contract_value function defined above, is to model with a normalized sales curve the market penetration and then the decay following the end of life of the patent and the entrance of competitors in the market. This sales curve can be empirically derived from previous launches, or artistically constructed like in the example shown here.
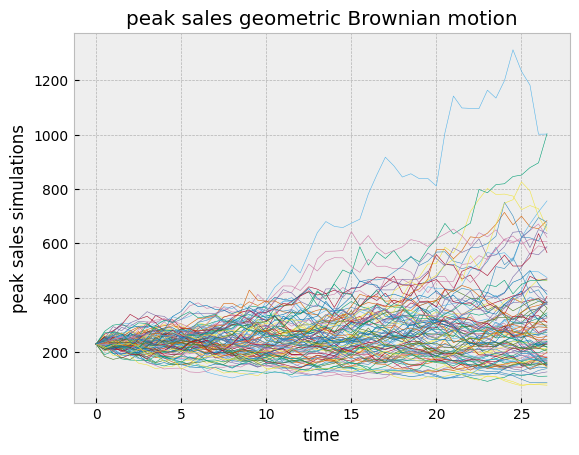
The sales can then be modelled with a single random variable, the peak sales, that will be multiplied by the sales curve. Since the estimation of the peak sales can vary over time because of external market conditions, modelling it as a stochastic process is a reasonable assumption. In practice, a geometric Brownian motion is a practical and realistic choice.
The variance increases over time, reflecting the increasing uncertainty of longer and longer forecasts.
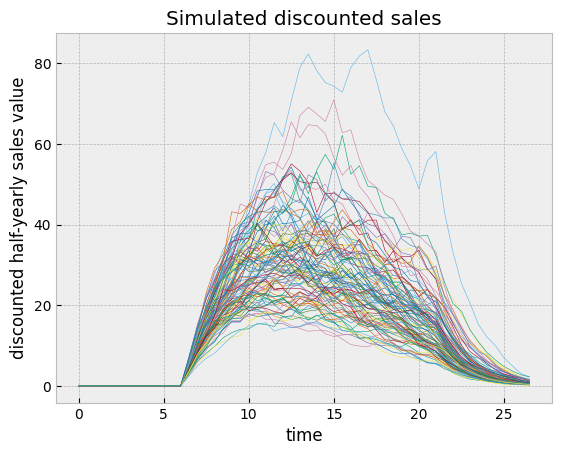
But when this peak sales stochastic process gets multiplied by the sales curve and the discount curve, the long term variance gets squeezed.
This somewhat controls the distribution of discounted total revenues.
The probabilistic financial model can be implemented as a TensorFlow Probability joint distribution parameterized by a distribution-making generator. This is well-suited for Monte Carlo simulations as mathematical operations can be directly expressed in JAX or TensorFlow code depending on the backend, while tensorflow_probability.distributions objects handle the random variables in the model.
Here it is assumed that the success rates and durations of clinical trial phases are known, but that the costs come with a 5% uncertainty and follow a normal distribution. Some metrics are extracted as tfd.Deterministic distributions so that they are recorded at sampling, the last one being the NPV of each realization of the simulator. The peak sales are modelled as a geometric Brownian motion as discussed above. If \(S_t\) obeys the stochastic differential equation
\[
dS_t = \mu S_t dt + \sigma S_t dW_t
\]
of a geometric Brownian motion, then its solution is given by
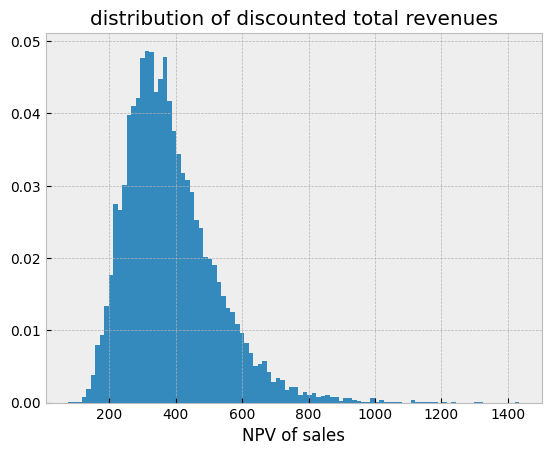
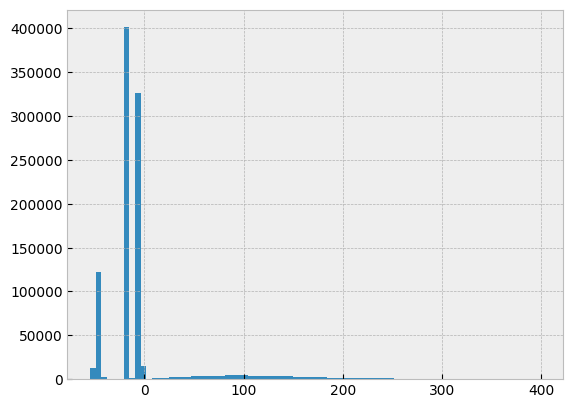
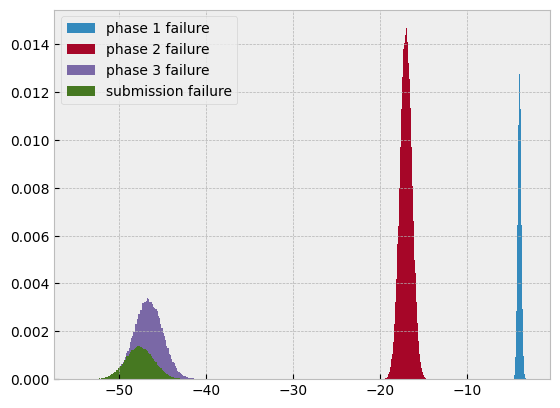
A histogram of the simulated NPV reveals four clusters, three of them corresponding to simulated failed programs, and a more diffuse one corresponding to the simulations that made it to commercialization.
Focusing only on the failed ones shows that the phase 3 and submission failures form a single cluster due to the relatively low submission cost.
Risk management through diversification
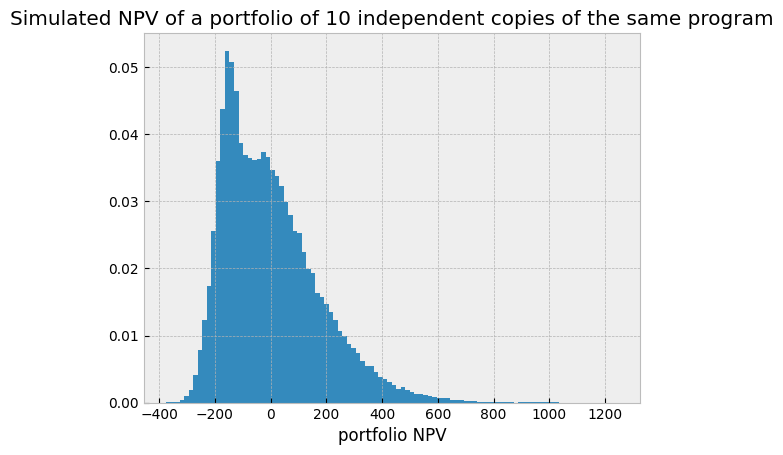
While the rNPV is really only a crude summary statistics of the distribution of potential outcomes, Monte Carlo simulations reveal how risky these investments can be and provide insights on how to mitigate those risks. The most immediate action is diversification. It reduces the variance and eventually merges the clusters. A simple model of a portfolio of 10 independent copies of the same drug development program considered above illustrates this mechanism.
The variance is reduced, but the probability of a negative value is still fairly high. If squeezing the variance tighter through even more diversification would help, shifting the distribution to the right through active optimization of its mean might be easier (and much cheaper) to implement.
Active optimization of the expected return
This is where differentiable programming and probabilistic programming nicely come together. The Monte Carlo estimation of the rNPV, which is the mean of the net present values of the simulated scenarios, is itself expressed in a differentiable program, and one can automatically compute its sensitivities.
A subtle technicality here is that the realizations of Bernoulli random variables are discrete and obstruct the propagation of gradients, but one can use the probabilities instead to build a differentiation-friendly estimator.
In practice, one cannot really directly change these variables, so at first glance these sensitivities are not very actionable. However, operational decisions on the execution of the trials typically involve trade-offs that can be hard to optimize. This problem can be addressed with differentiable chainable models. For instance, increasing the sample size should improve the success rate, which drives the rNPV up, but at the same time it increases costs and potentially delays commercialization, which drives the rNPV down. The overall change can be estimated by chaining the compute_rNPV function with dev_cost(sample_size) and success_rate(sample_size) functions, and computing the gradient with respect to the sample size variable.
Arguably, the models presented here have been known for a while, yet they are not always being used to their full potential in industry settings due to the technical challenges to implement them. By providing user-friendly APIs for Monte Carlo simulations and sensitivity computations, differentiable programming libraries will hopefully change that.