Code
# definition of parameters
a = 1.
b = 0.1
c = 1.5
d = 0.075
# initial population of rabbits and velociraptors
X0 = jnp.array([10., 5.])
# size of data
size = 100
# time lapse
time = 15
t = jnp.linspace(0, time, size)
saveat = SaveAt(ts=t)Machine learning algorithms are often criticized for their poor interpretability and a lack of uncertainty quantification. They are widely used nonetheless thank to modular libraries that allow us to build flexible models and training pipelines adapted to all kinds of problems. Automatic differentiation and specialized compilers are technologies at the core of those capabilities, and interestingly they have also been enabling rapid advances in the field of scientific computing, which naturally strives for interpretability and uncertainty awareness. Hamiltonian Monte Carlo and variational inference algorithms implemented in libraries such as PyMC, Pyro or TensorFlow-Probability are examples that immediately come to mind. When it comes to simulation, differentiable programming is gaining traction as it simplifies the process of calibrating computer models to experimental data. The idea is that the same principle as backpropagation in machine learning can be used to adjust the model parameters with gradient-based optimization algorithms until the simulated data closely matches the experimental data. The only requirement is that the model has to be written in a language that supports automatic differentiation.
For a long time, scientific computing relied on libraries written in Fortran, C/C++ or Python, or even MATLAB, by generations upon generations of graduate students and postdocs, and derivatives had to be calculated by hand (I sound like my grand-parents when they were telling me they had to walk several kilometers every day to go to school). Here comes JAX in the picture, a high-performance array computing library built around automatic differentiation and the XLA compiler, with a NumPy-like API that makes it easy to express scientific models in a code that will be differentiable and support hardware acceleration out of the box. Moreover, a whole ecosystem of specialized libraries have been built around JAX that can handle common scientific computing tasks, at a more or less high level, for instance:
The common JAX backend of these libraries allows for a great deal of modularity in the composition of scientific analysis pipelines. As an example, we will see how to quickly specify a predator-prey model in jax.numpy, integrate it with Diffrax, calibrate the resulting simulation to experimental data with Optax, and finally quantify uncertainties with a statistical analysis run in TensorFlow Probability on JAX. People who know me must now be thinking that I am a big fan of the JAX ecosystem because I come from a village called Nax, and they would not be completely wrong…
The Lotka-Volterra differential equations describe the time-evolution of the sizes of two populations of preys, denoted by \(x(t)\), and predators, denoted by \(y(t)\).
\[ \begin{aligned} \frac{dx}{dt} &= \alpha \, x - \beta\, x \, y \\ \frac{dy}{dt} &= \delta \, x \, y - \gamma \, y \end{aligned} \]
At first glance, these equations look relatively simple, but the quadratic terms make them painful to solve by hand. They are easily numerically integrated with the Diffrax library, which implements state-of-the-art integrators for differential equations.
The treatment of the problem presented here is inspired by the PyMC documentation and the corresponding tfp demo.
# definition of parameters
a = 1.
b = 0.1
c = 1.5
d = 0.075
# initial population of rabbits and velociraptors
X0 = jnp.array([10., 5.])
# size of data
size = 100
# time lapse
time = 15
t = jnp.linspace(0, time, size)
saveat = SaveAt(ts=t)But here we use a powerful integrator from Diffrax, further sped up with the magic of Just in Time compilation.
@jit
def competition_model(x0, y0, alpha, beta, gamma, delta):
# solves a Lotka-Volterra system of ODEs
# definition of the system of ODEs
def f(t, X, args):
return jnp.array([alpha * X[0] - beta * X[0] * X[1],
delta * X[0] * X[1] - gamma * X[1]])
stepsize_controller = PIDController(rtol=1e-5, atol=1e-5)
soln = diffeqsolve(ODETerm(f), Dopri5(), t0=0, t1=time, dt0=0.1,
y0=jnp.array([x0, y0]), saveat=saveat,
stepsize_controller=stepsize_controller)
return solnWe can generate synthetic observations with this solver to which we add a bit of noise to make the inference problems more realistic.
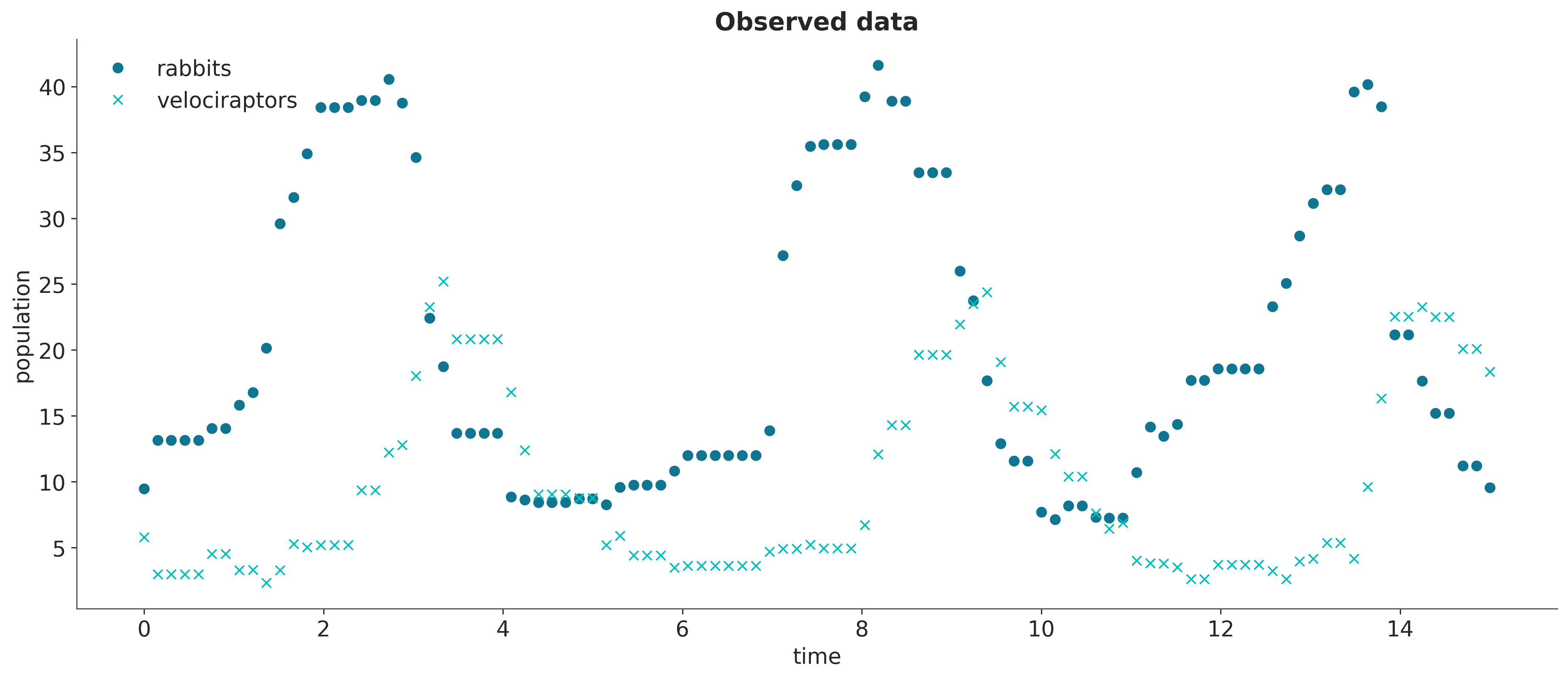
Since the Diffrax library is written in JAX, we can chain the numerical solution with a loss function that penalizes discrepancies between the simulations and the observations, and apply automatic differentiation on the output with JAX operators such as jax.grad.
To model the discrepancies, we assume that the observations are normally distributed around the simulated values, and construct a corresponding pseudolikelihood function.
epsilon = .5
kernel = tfd.Normal(0., epsilon)
@jit
def pseudolikelihood(x0, y0, alpha, beta, gamma, delta):
sim_data = competition_model(x0, y0, alpha, beta, gamma, delta)
error = observed - jnp.stack(sim_data.ys)
return jnp.mean(kernel.log_prob(error))To find the best fit parameters, we can then maximize this pseudolikelihood with an optimizer from the Optax library.
params = jnp.array([5., 5., 1., 1., 1., 1.])
start_learning_rate = 1e-1
optimizer = optax.adam(start_learning_rate)
opt_state = optimizer.init(params)
@jit
def compute_loss(params):
return -pseudolikelihood(*params)
# A simple update loop.
for _ in range(1000):
grads = grad(compute_loss)(params)
updates, opt_state = optimizer.update(grads, opt_state)
params = optax.apply_updates(params, updates)
# computing the best fit solution
fitsoln = competition_model(*params)| true value | estimated value | |
|---|---|---|
| parameter | ||
| x_0 | 10.0 | 10.176 |
| y_0 | 5.0 | 3.917 |
| alpha | 1.000 | 0.821 |
| beta | 0.100 | 0.091 |
| gamma | 1.500 | 1.854 |
| delta | 0.075 | 0.095 |
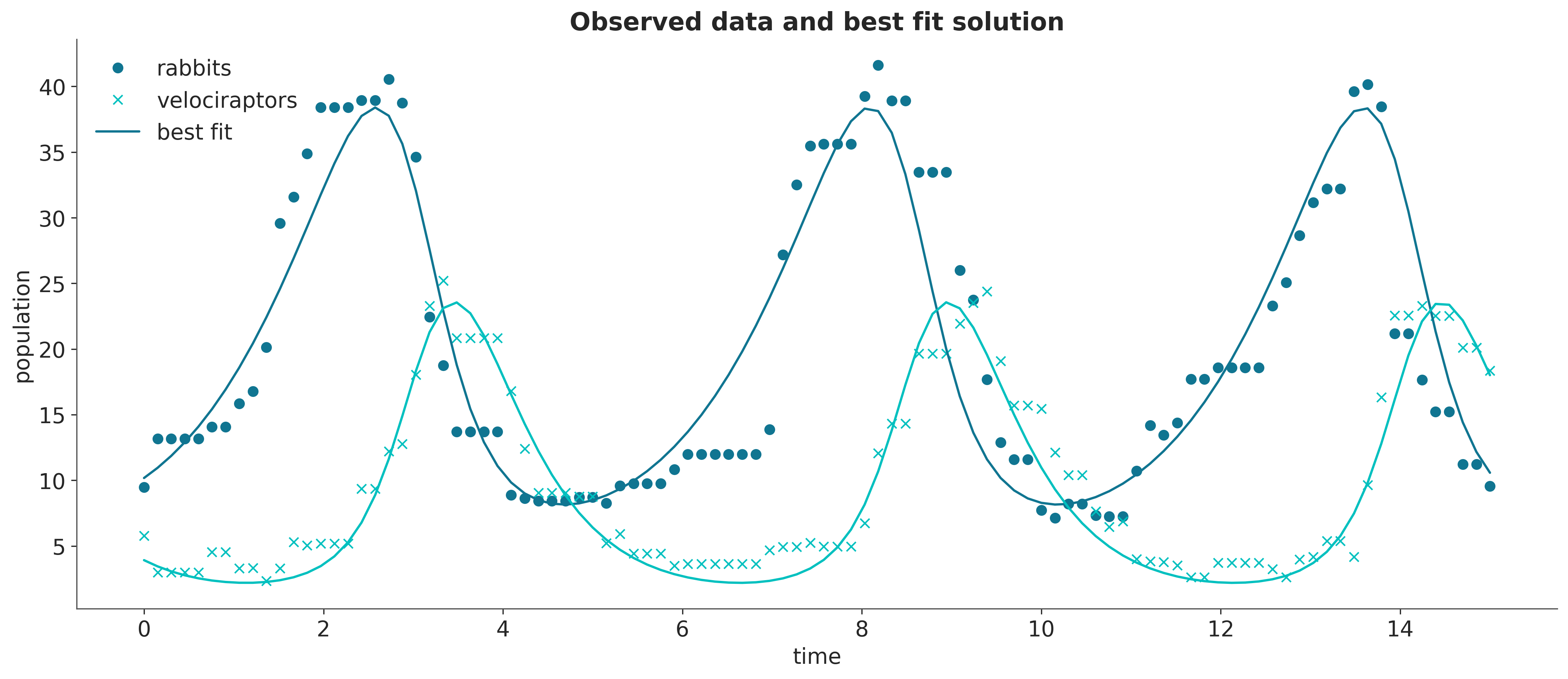
The estimated values do not quite match the true parameters, and it would certainly be interesting to get error bars. A Bayesian analysis is a convenient way to achieve this, so the first step is to specify a prior distribution on the parameters.
ode_prior = tfd.JointDistributionSequential([
tfd.Normal(X0[0], .25),
tfd.Normal(X0[1], .25),
tfd.Normal(1., .5),
tfd.Normal(.5, .1),
tfd.Normal(2., .5),
tfd.Normal(1., .1),
])Samples from the corresponding prior predictive distribution of the observed data provide a good sanity check of the choice of priors.
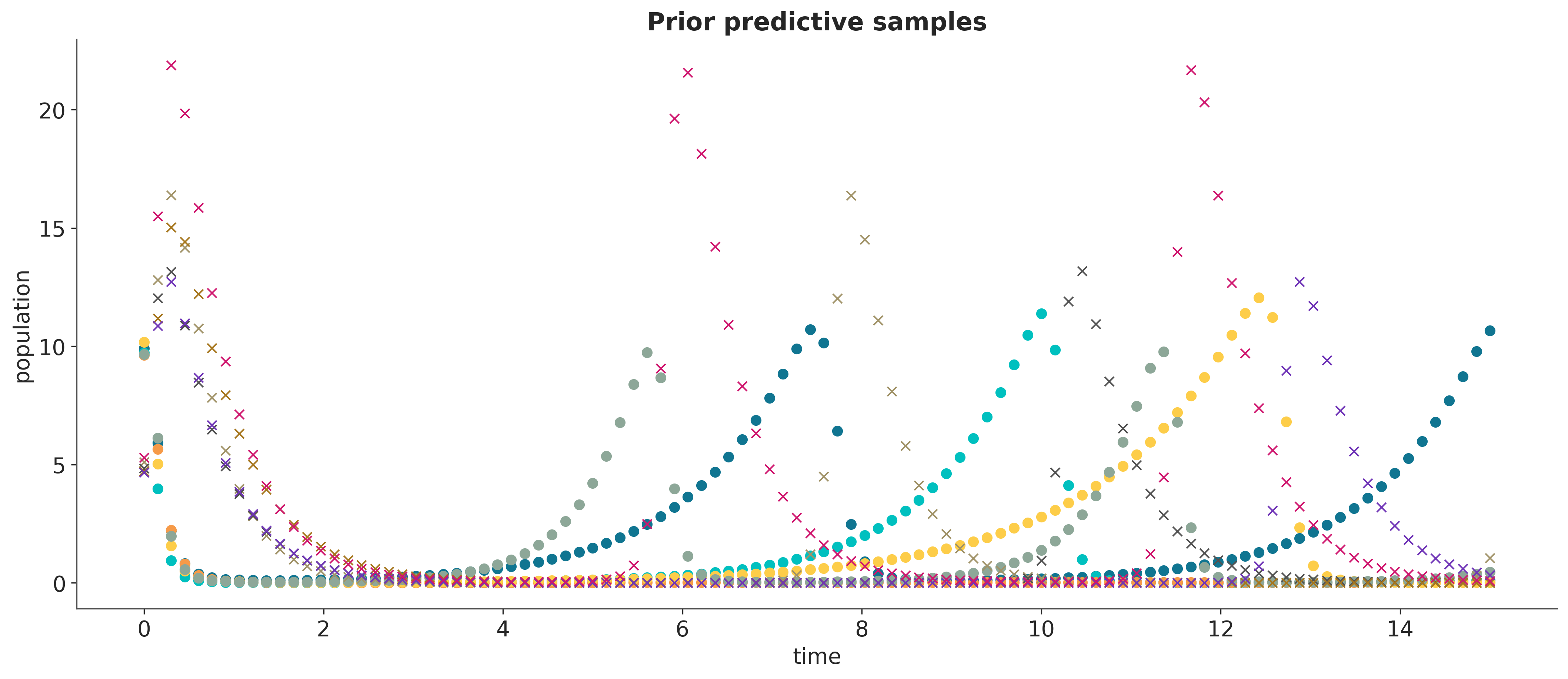
The problem now is that we cannot build a joint distribution of the parameters and the observations reflecting our model assumptions that there is an underlying ordinary differential equation governing the dynamic of the system. As a result, we cannot derive a likelihood function that is required by the usual MCMC and variational inference algorithms for Bayesian statistics.
As a workaround, there exist some likelihood-free inference algorithms for models where we know how to simulate data, but not how to construct a likelihood function. This is the case for a significant portion of scientific models, and the research field of simulation-based inference is growing to address this need. Approximate Bayesian computation is a family of such algorithms (see this review article for more details). It includes a variant of sequential Monte Carlo (SMC) that can be implemented in PyMC and TensorFlow Probability, which we will be using here.
This algorithm requires a batched version of the pseudolikelihood function, so that it can be applied to a large sample of model parameters, the so-called particles, in parallel. For every particle, the batched pseudolikelihood function calls the differential equation solver, so a simplified version of the solver with no timestep adaptation can help avoid maximum timesteps errors.
@jit
def batched_competition_model(x0, y0, alpha, beta, gamma, delta):
# solves a Lotka-Volterra system of ODEs
def f(t, X, args):
return jnp.array([alpha * X[0] - beta * X[0] * X[1],
delta * X[0] * X[1] - gamma * X[1]])
soln = diffeqsolve(ODETerm(f), Dopri5(), t0=0, t1=time, dt0=0.1,
y0=jnp.array([x0, y0]), saveat=saveat)
return soln
@jit
def batched_pseudolikelihood(x0, y0, alpha, beta, gamma, delta):
sim_data = batched_competition_model(x0, y0, alpha, beta, gamma, delta)
error = observed[...,jnp.newaxis] - jnp.stack(sim_data.ys)
return jnp.mean(kernel.log_prob(error), axis=[0, 1])A typical SMC sampler requires a prior density function and a likelihood function to build a sequence of (unnormalized) density functions between the prior and the target posterior we are interested in (for a thorough introduction to SMC algorithms, see chapter 13 of Probabilistic Machine Learning: Advanced Topics). It then applies a particle filter algorithm to get samples of these density functions until the final one provides the desired output. In SMC-ABC, the likelihood function is replaced by a pseudolikelihood function.
sample_smc_chain = tfp.experimental.mcmc.sample_sequential_monte_carlo
@jit
def run_abc():
n_stage, final_state, final_kernel_results = sample_smc_chain(
prior_log_prob_fn=ode_prior.log_prob,
likelihood_log_prob_fn=batched_pseudolikelihood,
current_state=ode_prior.sample(1000, seed=sample_key),
min_num_steps=5,
seed=sample_key,
)
return n_stage, final_state, final_kernel_results
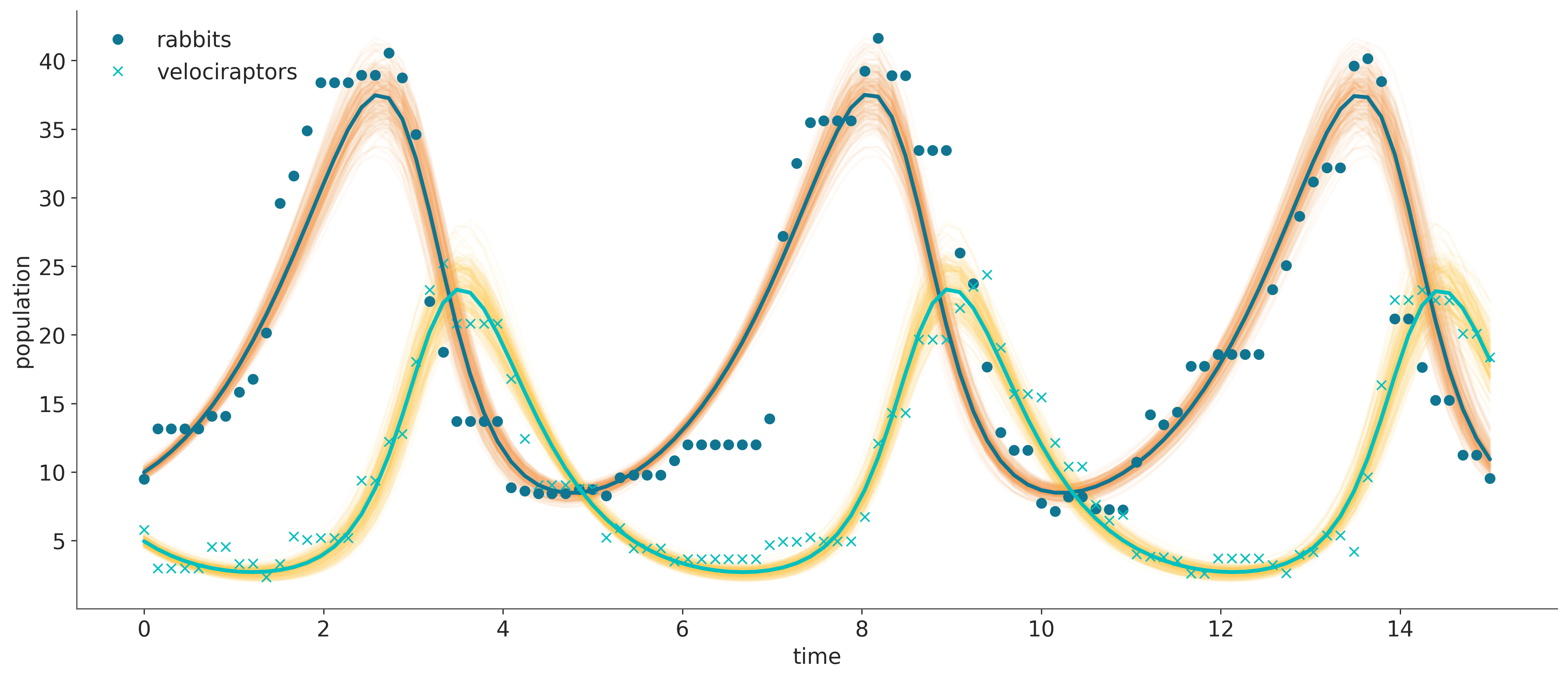
n_stage, final_state, final_kernel_results = run_abc()The final state of the particle filter is a sample from the (approximate) posterior distribution.
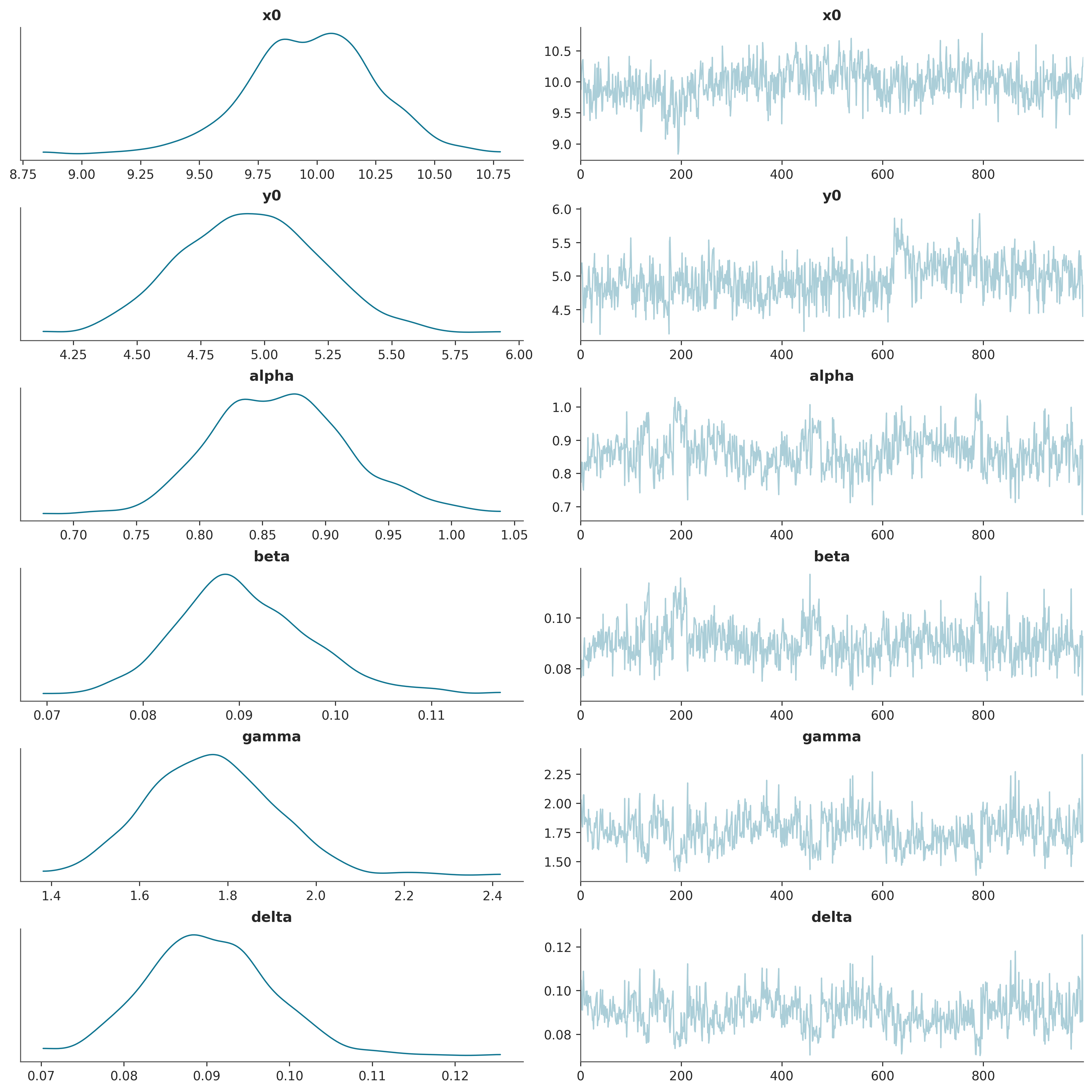
The posterior standard deviations provide the desired uncertainty quantification for the parameter estimates.
| true value | posterior mean | posterior std | |
|---|---|---|---|
| parameter | |||
| x_0 | 10.000 | 9.975 | 0.269 |
| y_0 | 5.000 | 4.949 | 0.277 |
| alpha | 1.000 | 0.864 | 0.055 |
| beta | 0.100 | 0.091 | 0.007 |
| gamma | 1.500 | 1.761 | 0.142 |
| delta | 0.075 | 0.090 | 0.007 |
Lastly, we can simulate trajectories for parameters from the posterior sample to visualize the posterior predictive distribution of populations and compare it with the observations.